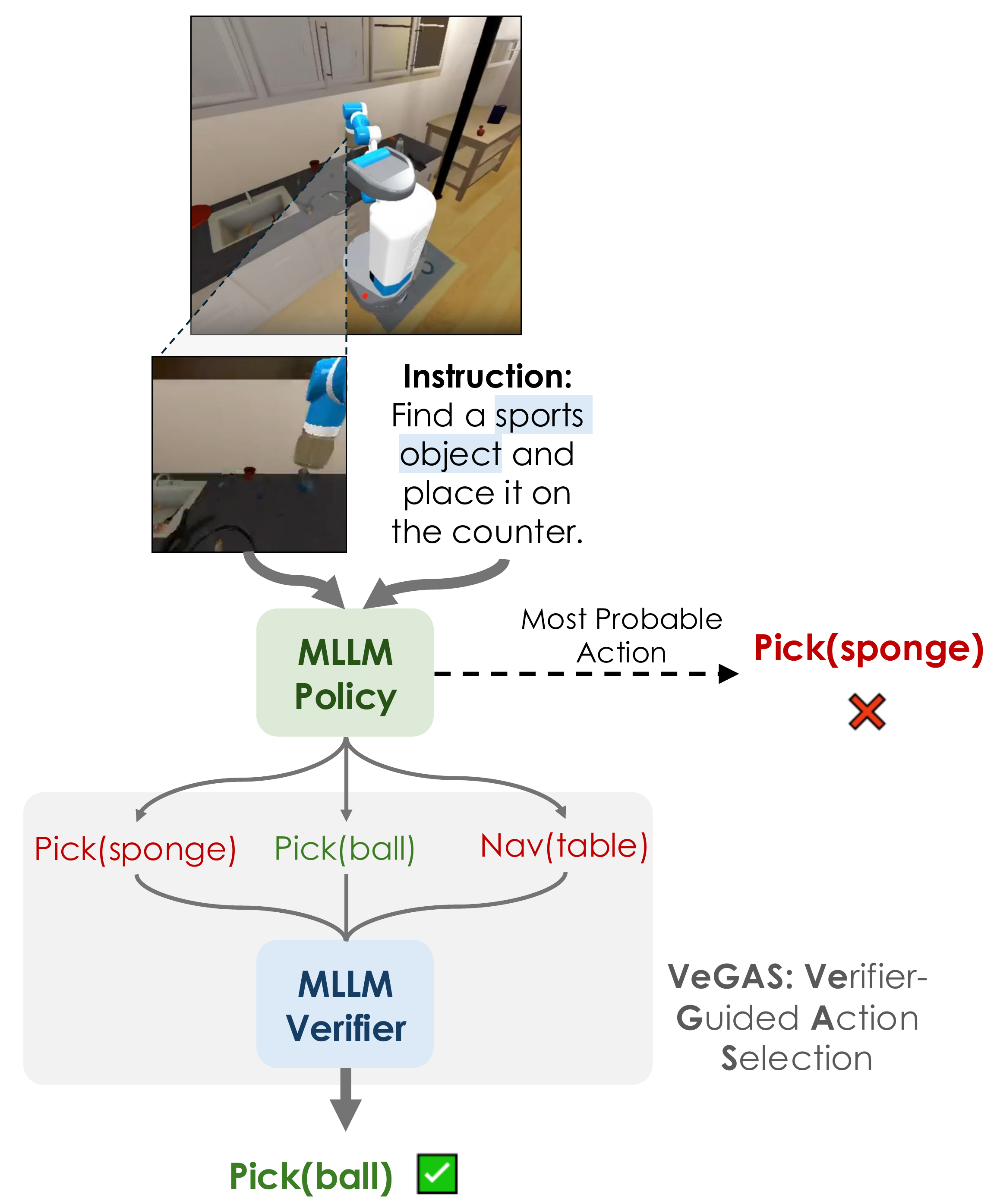
We give embodied agents a moment to think. At inference time, instead of committing to the first action a multimodal LLM produces, we draw a handful of candidates and let a small, specifically trained verifier pick the most reliable one. The result: consistent gains on out-of-distribution embodied tasks (up to +36% relative on the hardest multi-object scenarios), with no change to the underlying policy.
Multimodal LLMs make surprisingly capable embodied agents: hand them an instruction like “bring me a banana” and they will navigate the kitchen and pick the right thing. But the moment the world tilts, performance falls off a cliff. A paraphrased instruction (“a yellow curved fruit”), an extra object, or a longer chain of subtasks is enough.
We trace this fragility to a simple fact: the agent commits to a single greedy action at every step. There is no chance to consider an alternative or catch a small error before it compounds. Humans don’t act this way. We weigh a few options, mentally check each, and then move. We verify before acting.
VeGAS runs entirely at inference time. At every timestep, the policy proposes N candidate actions, each with a chain-of-thought rationale. A separate generative verifier reads each candidate, writes its own short rationale, and emits a verdict (yes / no). We average M verdicts per candidate to get a stable score, then execute the highest-scoring action. The base policy is untouched.
Using the same MLLM as a zero-shot verifier doesn’t help. In fact, it slightly hurts (see the Zero-shot Verifier rows in the tables below). General language understanding is not the same as the ability to judge whether this action, in this scene, advances the goal. Verification is a distinct skill, and it has to be learned.
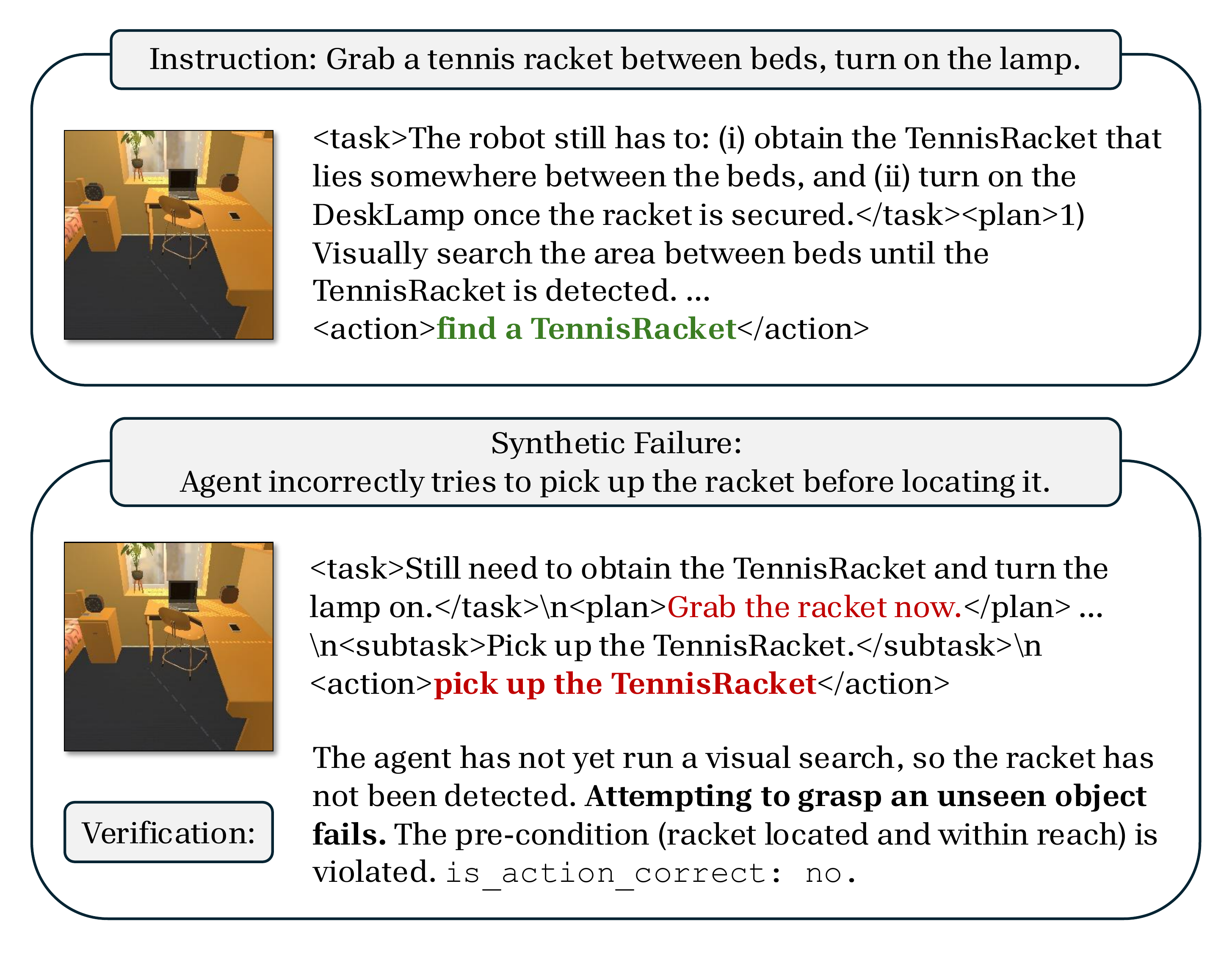
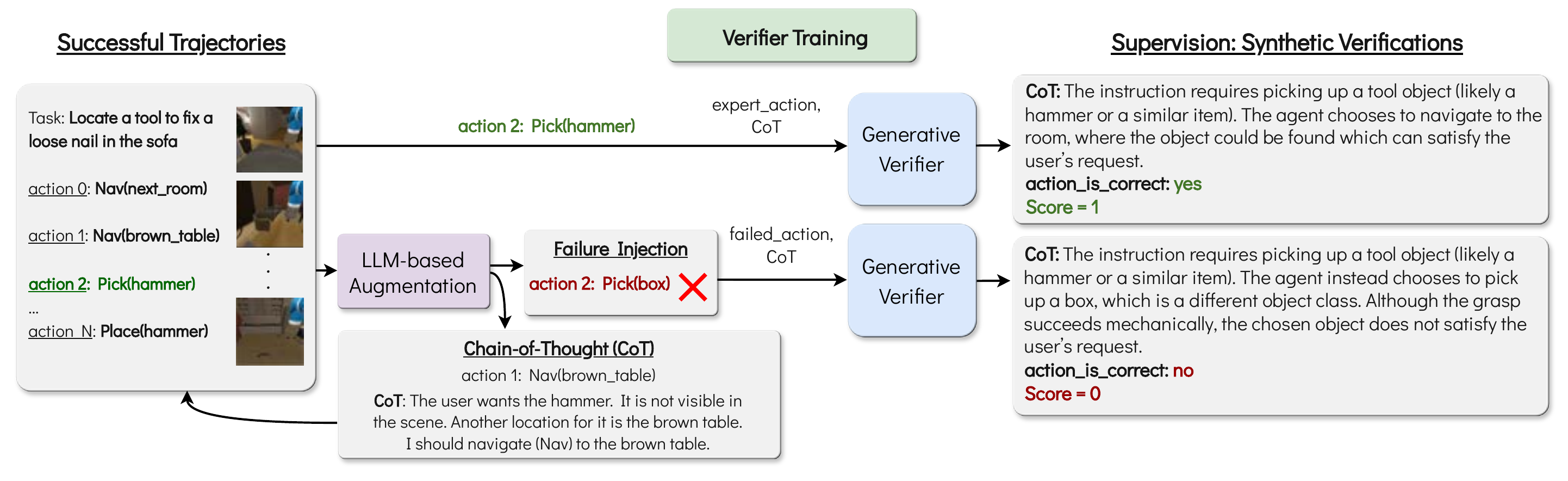
Training a verifier requires paired examples of correct and incorrect actions, each annotated with a rationale explaining why. No standard embodied benchmark provides this, so we synthesize it. Starting from a small set of expert demonstrations, we use an LLM to do two things for every action: (1) annotate the correct action with a chain-of-thought rationale, and (2) generate a plausible failed twin (the kind of mistake a real policy would actually make) paired with a rationale explaining the error. Finetuning an MLLM on this paired corpus yields a verifier tuned to the failure modes that matter, without any new human annotation.
On both benchmarks, the same recipe holds: chain-of-thought is a strong baseline; an off-the-shelf verifier doesn’t move it; our finetuned verifier does.
| Approach | Average | Paraphrastic Robustness | Behavioral Generalization | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rephrasing | Context | Irrelevant Text |
Referring Expressions |
Multiple Rearrange |
Novel Objects |
Multiple Objects |
Conditional | ||
| Prior work | |||||||||
| LLaRP (LLaMa-7B) | 46 | 92 | 34 | 32 | 26 | 47 | 95 | 0 | 39 |
| SemLang (LLaVA-1.5-7B) | 58 | 92 | 46 | 66 | 31 | 80 | 97 | 2 | 46 |
| Policy only (Qwen-2.5-VL-3B-Instruct) | |||||||||
| No-CoT | 58 | 93 | 39 | 72 | 48 | 68 | 97 | 17 | 28 |
| w/ CoT | 65 | 98 | 50 | 85 | 59 | 64 | 97 | 25 | 42 |
| w/ CoT policy + Verifier (Qwen-2.5-VL-3B-Instruct) | |||||||||
| + Zero-shot Verifier | 64 | 98 | 50 | 85 | 48 | 65 | 97 | 30 | 40 |
| + Finetuned Verifier (VeGAS) | 71 (+6) | 99 | 52 | 92 | 62 | 82 | 97 | 34 | 48 |
| Approach | Average | Base | Common Sense |
Complex Instructions |
Long Horizon |
Spatial | Visual Appearance |
|---|---|---|---|---|---|---|---|
| Qwen-3B w/ CoT | 44 | 62 | 40 | 58 | 22 | 34 | 48 |
| + Zero-shot Verifier | 44 | 64 | 41 | 53 | 24 | 35 | 46 |
| + Finetuned Verifier (VeGAS) | 49 (+5) | 67 | 46 | 62 | 34 | 43 | 41 |
| Approach | Average | Base | Common Sense |
Complex Instructions |
Long Horizon |
Spatial | Visual Appearance |
|---|---|---|---|---|---|---|---|
| Gemma-4B w/ CoT | 48 | 62 | 50 | 56 | 28 | 34 | 56 |
| + Zero-shot Verifier | 48 | 66 | 55 | 61 | 27 | 32 | 49 |
| + Finetuned Verifier (VeGAS) | 51 (+3) | 67 | 56 | 67 | 25 | 37 | 53 |
A 3B verifier improves much larger policies it was never trained with. Pair it with an off-the-shelf 27–72B MLLM acting zero-shot, and the verifier still picks better actions than the policy alone, despite being up to ~20× smaller. Verification skill, learned once, transfers across model families and scales.
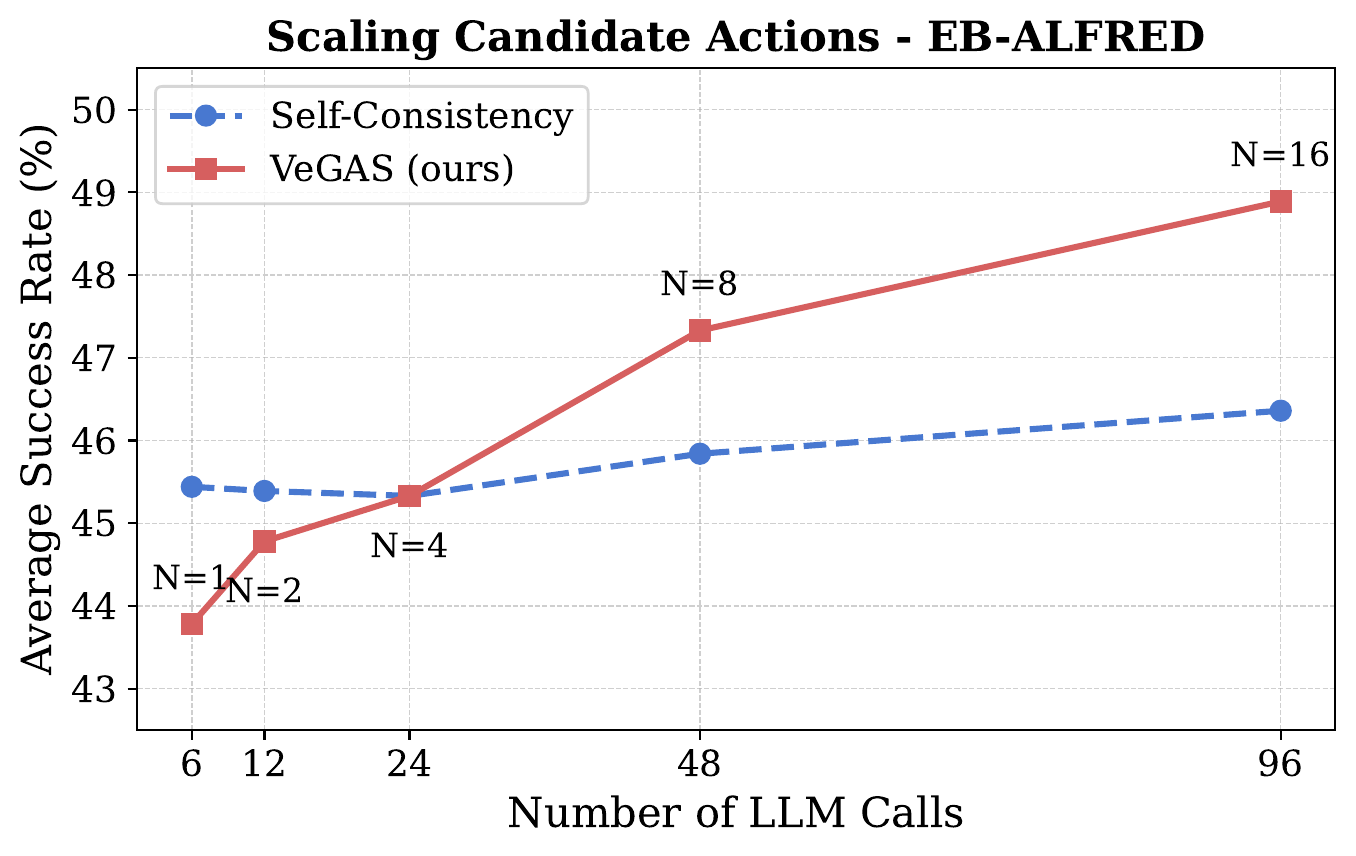
A natural question: are the gains just from sampling more actions? We compare against self-consistency (majority vote over samples) under the same total compute budget. VeGAS scales much better, showing that a learned verifier is what unlocks test-time compute as a meaningful lever for embodied reasoning. Without it, extra samples buy you almost nothing.
And latency stays reasonable: even with N=8 candidates and M=5 verifications each (48× the LLM calls of greedy decoding), wall-clock latency only doubles, because every sample runs in parallel.




@article{singhi2026vegas,
title = {Think Twice, Act Once: Verifier-Guided Action Selection for Embodied Agents},
author = {Singhi, Nishad and Bialas, Christian and Jauhri, Snehal and
Prasad, Vignesh and Chalvatzaki, Georgia and
Rohrbach, Marcus and Rohrbach, Anna},
journal = {arXiv preprint},
year = {2026}
}


